Example of SLODLC Discovery Worksheet
Service Name: Chatbot
SLODLC Adoption: Project “SLOtisfactionary Chatbot”
SLO Adoption Leader: John Smith, Senior PM, jsmith@bestprepaidgsm.com
Worksheet Owner: Joe Doe, SRE, jdoe@bestprepaidgsm.com
Document Status: Example Draft
Related Docs: EXAMPLE of 1. SLODLC Business Case Worksheet v1.1
Discovery Worksheet Scope
- Service
- Prioritize User Journeys & Expectations
- Analyze Dependencies
- Observe System Behavior
- Memo/Notes
How to work with Discovery Worksheet
- Please walk through each point in the table
- Each point consist of a question section and instructions section
- Provide clear, written answers
- Provide URLs/Links for external resources if any
- Explicitly refer to necessary attachments if any
- Return this completed form, with any necessary attachments, to: …
- If you have any questions about this form, please contact: …
1.Service
1.1.Service description
Provide basic information about the service, its name, description - what is the service goal and scope; outline service boundaries, dependencies outside your control; the impact of unreliability, what performance characteristics are the most important, any existing expectations.
The Chatbot is an online service that simulates a human being with which you can talk in natural language. The task of such a service is to act in an intelligent conversation with a person on various topics. The conversation runs through a text interface. Chatbot service allows you to familiarize yourself with the offer, and he can guide you through the entire process of purchasing. The seller's chatbot tasks also include getting to know the client's expectations.
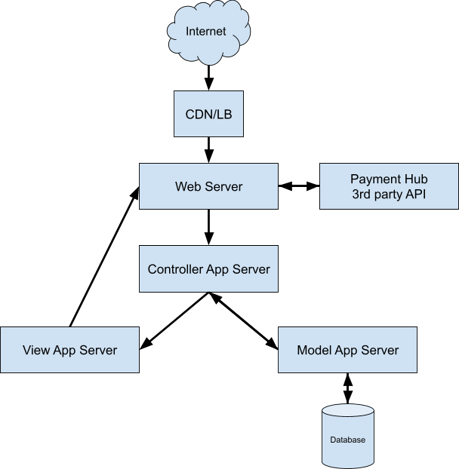
Service Overview: For the first iteration of Discovery, we will focus on Web Server and Chatbot servers - Ruby on Rails e-commerce solution in MVC architecture (Model (M), View (V), and Controller (C)) with Web Server. Functionalities are as follows: Built-in content management system with blog solution, Payment/Transactions 3rd party hub, Products and customer orders management, Sales reports, Admin panel.
The sole Chatbot service is built upon the dedicated architecture - Chatbot modules (ActiveRecord, ActionView, ActionController), JavaScript templates for generating scripts with AJAX, RR plugins for data validation. Controller/Model/View APP servers are collocated - we can ignore internal latency.
Database: MySQL with product library and Chatbot linguistic library
1.2.Owner and Stakeholders
Provide information about key stakeholders.
- Service Owner: Daniel Burton, IT Director
- Service Stakeholders: John Smith, Senior PM; Joe Doe, SRE; Chatbot Team (Developers, DevOps); Ellis Carr, Product Owner; All online Customers
1.3.Service Business Context
Provide information about business context in the table below.
- Question: Who cares about this service?
- Answer: Sales and IT staff is vitally interested in the flawless operation of this service as it is a part of the market advantage of the company; Customers care about quick and straightforward Chatbot help providing them the exceptional online shopping experience
- Question: Why do they use it?
- Answer: Customers use Chatbot service because it is a primary way to search for the desired product; it is simple interaction with a human-like selling advisor, natural and effective. An innovative and friendly approach makes this service a preferred one - Chatbot is represented by an animated avatar. In the future the company is planning to add text-to-speech features to make the conversations even more natural.
- Question: What happens if they can’t?
- Answer: Customers like Chatbot's ease of use as providing simple answers. They receive hints about what product suits their needs, and extra product comparisons help to make the best decision. Customers tend to come back to this online shop because of satisfaction with buying experience.
- Question: What alternatives do they have?
- Answer: As an alternative to Chatbot - there is a typical online shop experience with text function search and product directory to navigate with filters.
- Question: At what point will they leave or try again?
- Answer: Most of the data indicate that slow conversation with the bot (long times of waiting) and slow preparation of offers impact customer satisfaction.
- Question: How does this service support our business goals?
- Answer: Chatbot service is pivotal for business modus Operandi to provide fast and reliable customer help - our online wants to provide fast and accurate automated customer assistance.
- Question: What is the estimated volume of business transactions or user transactions on the service?
- Answer: We have around X daily unique visitors where Y are using our Chatbot, and only Z tends to use classical product experience. We sell around N products a day (sales online process finished successfully with payment).
- Question: What $ amount does that represent and what % of the overall business is that?
- Answer: Daily revenue generated by this service on average is X, and that channel is 80% off wholesale volume.
1.4.Service Expectations
1.4.1.Service Level Agreements with their levels
Provide information/list about active SLAs and levels related with the service, rank them by criticality. Explain consequences of the SLAs.
- SLA: The business Sales Department has an internal Chatbot SLA with IT Team for 99% Chatbot availability and response latency of 200ms per Chatbot answer.
- Consequences: Going below SLA agreement will impact companies planned revenues and customer satisfaction.
1.4.2.Who defined reliability expectations, who is responsible for achieving them?
Provide description per item from 1.4.1; name stakeholders - OPTIONAL.
The sales Department clearly defines reliability expectations, and the Chatbot Team is responsible for achieving them. There is an informal SLA in place for this service.
1.4.3.Unwritten/informal expectations towards services, and who stands behind those?
Provide information - this might be a case of not having a sufficient number of targets defined where outages might result in measurable losses; what stakeholders are interested and why.
The Sales Department and Companies Board wish to have Chatbot always perfectly reliable as a service. Both forces change for internal SLA in the future. The cloud transition project is on the company roadmap, and it is also related to increasing Chatbots reliability which will translate on company revenues.
1.5.Pain Points
1.5.1.What are the existing pain points of the services you are aware of?
Check if any of the most common pain points do exist; add extra identified pain points. Most common pain points: Business-oriented insights, Customers happiness (churn), Customers happiness (other), Employees happiness (attrition), Employees happiness (burnout), Failures with innovation ideas, Feature vs. reliability decision making, Go-fast vs. go-safe, Over alerting (too busy responding to incidents), Service scaling, Technical debt removal.
- Feature vs. reliability decision making
- Employees happiness (lack of growth)
1.5.2.Elaborate on Pain Points
For those pain points that are identified above (in 1.5.1) - prepare an overview description below.
- The company's Board of Directors is taking Chatbot reliability as the main business driver. This leads to stagnation with the development of new features as a reliability risk mitigation. The company wants to move slowly with new features as they value safe and predictable business over innovation.
- The above situation contributes to a general unsatisfactory work environment in the IT Department, where employees are not developing and learning. They spend time with code refactoring and maintenance most of the time, not developing new features.
2.Prioritize User Journeys & Expectations
2.1.Define The Users of the service
Provide information; a list of Users of the service, every stakeholder interacting (internal, external) or other interacting services. Instead of listing particular Users, you may consider groups of users and their classification; name those groups.
- Internal (company employees)
- Chatbot Team (Developers, DevOps) - technical employees fully responsible for this online service
- Sales Department - business employees fully responsible for this online service
- Chatbot Team and Sales Department - are connected with internal service SLA
- External (customers/external service users) - we will focus with SLOs on this group in the first iteration 4. All customers visiting online shop using Chatbot services
2.2.Users Journeys
Provide description or a diagram of The User Journey with their boundaries - for all listed Users in 2.1; you might use your architectural diagrams or other dedicated documentation. As an alternative, use user cases/stories, process flows.
We will use the service diagram from point 1.1 with 2 critical customers/external service users' journeys (customers visiting our online shop using Chatbot services).
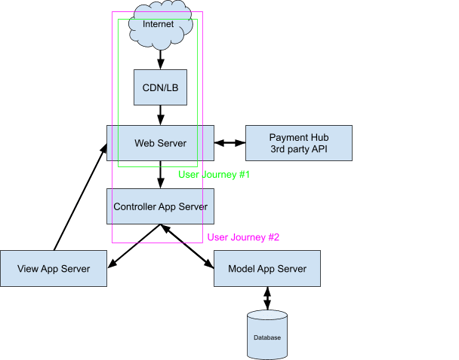
We will focus on 2 User Journeys in the first Discovery Iteration:
- Latency and availability of online shop web servers are essential to both customers and the company. Customer experience with us is translated by happiness and satisfaction; latency of online shop is the number one factor contributing towards that.
- Latency of Chatbot - latency between Web Server and Controller App server is the primary customer activity on our website, which contributes to customer happiness and satisfaction. We want our Chatbot to be responsive and meet customers' expectations and that is by having exceptional latency.
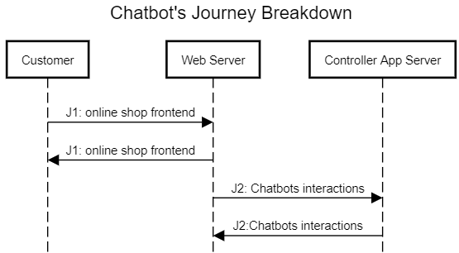
2.3.User Expectations per Journey
Provide additional information about clear User Expectations related to defined User Journeys (in 2.2); what will make The User happy during their Journey and where are the boundaries? You may find many different expectations for one Journey or even for one interaction.
- User Journey 1 - The customer experience with latency using the online shop website translates to Customer Happiness and satisfaction. The online shop should be accessible at any time (this experience will be elaborated on in the second iteration of Discovery for this service).
- User Journey 2 - The customer is expecting low latency for Chatbot responses; Chatbot should answer questions very fast for generic product questions (according to our experience - this is necessary for exceptional customer experience); Controller/Model/View APP servers are collocated - we can ignore internal latency.
2.4.Prioritize
2.4.1.Prioritize Expectations
Using list from 2.3 prioritize all User Expectations top-down, from most important to less important, according to impact on User happiness and your business. Important - prioritization is about having clear ranking with one attribute per rank - this is a common misconception - making for instance, 2 attributes same important.
- Low latency using the online shop website (User Journey #1)
- Low latency for Chatbot responses (User Journey #2)
- Shop daily availability (for next iteration of this Discovery) (User Journey #1)
3.Analyze Dependencies
3.1.Architectural dependencies and constraints - Adjust Priorities
Using your priority lists according to User Journeys and Expectations, look from the perspective of your IT Systems Architecture (databases, networking, container orchestration, virtualization) and Services Architecture (coexisting services, microservices, APIs ), look for dependencies and constraints that might impact priorities. Reprioritize - apply changes if needed. Hard Dependencies are all those dependencies which directly impact reliability expectations; Soft Dependencies or dependencies which are important but without direct impact on reliability expectations.
For our selected customer experience instances - we don't see any special dependencies that might influence. This is a simple journey with a simple flow but crucial for a happy customer experience. Controller/Model/View APP servers are collocated within our on-premise datacenter - we can ignore internal latency between them.
3.2.Dependencies and Constraints - Adjust Priorities
Using your priority lists according to User Journeys and Expectations look from the perspective of all User Journeys, crossing each other - having cross impact. Reprioritize - apply changes if needed.
For our selected customer experience instances - we don't see any special constraints and dependencies. Selected User Experience instances are clear and simple as we are at the beginning of our SLO adoption and we want to practice with simple ones and fastest to implement.
3.3.Process Governance - OPTIONAL
3.3.1.Service Agreements Management Process
Describe the Service Agreement Process and how you manage reliability targets, especially, how you create, update and manage decisions off your reliability metrics - OPTIONAL.
Our company decided to have a simple internal SLA between IT and Business units for Chatbot - SLA of 99% Chatbot availability and response latency of 200ms per Chatbot answer. Our company doesn't have any special Service Management process or procedure, we define SLAs ad hoc.
3.3.2.Incidents and Problems Management Process
Describe the process on how you declare and manage Incidents and Problems until service restoration - OPTIONAL.
We are following best industry practices for incident management. We use a standardized incident process implemented in the dedicated, market popular, incident tool - we use a standard tool flow without special customization. All incidents are logged and categorized. We prioritize incidents and assign them to operators. Dedicated tasks are created and managed towards a successful resolution. We use internal SLA management and best practices, we escalate incidents according to set triage rules. Resolved incidents are reviewed and closed with a dedicated postmortem.
4.Observe System Behavior
4.1.List ten outages with business impact description
Provide examples in a list of five high business impacting outages or degradation of the User Journeys.
- User Journey 1 - our dedicated hosting provider didn't inform us about load balancer configuration upgrade, which resulted in slow network routing - Customers were experiencing high latency spikes using our online shop.
- User Journey 2 - we experienced high traffic and Chatbot usage, multiple active instances of Chatbot resulted in Web Server memory leak; we had to upgrade our Web Server infrastructure.
4.2.Cases studies of outages with business impact description
Provide details for the top-five from above list (4.1).
- User Journey: User Journey 1
- Service: Web Server
- Business Impact ($/Reputation): Low sale volume during incident day; sale daily targets were not achieved
- Mitigation Response: We updated our procedures with hosting provider
- User Journey: User Journey 2 4. Service: Chatbot 5. Business Impact ($/Reputation): Low sale volume during incident day; sale daily targets were not achieved 6. Mitigation Response: We upgraded our APP Server infrastructure - RAM added
4.3.Data
4.3.1.Data sources
Please provide a list of your Observability System (Data Source), metrics for each of the services.Describe briefly data sources used for your present SLIs defined for the service across user journeys.
- Service: Web Server
- Metrics: Latency
- Observability System (Data Source): DataObserverOne
- Service: Chatbot 3. Metrics: Latency 4. Observability System (Data Source): DataObserverOne
- Service: Web Server 5. Metrics: Availability 6. Observability System (Data Source): DataObserverOne
4.3.2.Retention policies
Describe data retention policies explaining what data is stored, where data is stored, how long data is stored (raw data and downsampled data) per item from your list in 4.1.1.
- Data Source: DataObserverOne
- Data Retention Period: 365 days logged
- Data Downsampling Time: Non, raw data only
4.3.3.SLIs
Provide SLIs with methods of calculation for your service - if there are any already in place. Provide information about SLIs Labeling methods and standards - if there are any defined in your organization.
We already have 2 SLIs in place and working.
- Web Server Latency SLI: proportion of requests served successfully; Proportion of HTTP GET requests for Web Server that have a response in 600ms (successful), measured at Web Server
- Chatbot Latency SLI: proportion of requests served successfully; Proportion of “Chatbot responses” for Web Server that have a response in 200ms (successful), measured at Web Server
4.4.Alerting
4.4.1.Alerting tools
Check if you are using any of the listed alerting tools. Most common ones: Discord, Email, Jira, MSTeams, Opsgenie, PagerDuty, ServiceNow, Slack, Webhook. Add others if needed. Describe briefly alerting tools used for your present SLIs defined for the service across user journeys.
We use a combination of Slack and Emails for alerting purposes. If SLI is breached, dedicated messages are triggered in both communication channels plus using PagerDuty. We react ad hoc. An Incident is created.
4.4.2.Alerting policies with escalation patterns
Provide examples of existing alerting policies for the service; describe practices related with triaging incidents.
- Alerting Policy: Any latency SLI breached
- Triaging Incidents (escalation patterns): Alerting in all channels, incident created and handled immediately by administrator; No special triaging - we work ad hoc
5.Memo/Notes
Meeting
Provide information about Discovery Workshop - date/place.
First Discovery session meeting, drafting Discovery Worksheet 4/24/2022
Attendees
Provide information about Discovery Workshop - who/contacts.
John Smith, Joe Doe, Ellis Carr, Chatbot Team
Agenda
Provide information about topics discussed.
- Round table discussion
- Preliminary document drafting
Action Items
Provide information about any particular to do’s.
- John Smith, Senior PM - till the end of the month, finalize Discovery Worksheet with internal Stakeholders, get approval from the whole Chatbot Team
Decisions
Provide information about any particular important decisions made.
- All attendees agree and commit to the defined project goals.
Notes
Place for any relevant notes to be captured.
- This document and all others will be available to the whole company as we want to make SLO adoption visible.
This template is part of SLODLC https://www.slodlc.com/release-notes/license